Python Best Practice: List Operation
Brief Introduction of List Comprehension, Map & Filter, Sort, zip and precaution when generating a list of single item

1. Introduction
This blog introduces some best practices when handling list in Python.
2. List Comprehension
List comprehension means that you can contruct a new list from an existing list in a line.
fruits = ["apple", "banana", "cherry", "kiwi", "mango"]
upper_fruits = [ fruit.upper() for fruit in fruits ]
print(f'{ upper_fruits= }')
# upper_fruits= ['APPLE', 'BANANA', 'CHERRY', 'KIWI', 'MANGO']
fruits_with_a = [ fruit for fruit in fruits if "a" in fruit ]
print(f'{ fruits_with_a= }')
# fruits_with_a= ['apple', 'banana', 'mango']
We can also use list comprehension to generate 2-dimentional array (or n-dimentinal array)
row_amount = 3
col_amount = 2
two_dimentional_arr = [ [ 1 for _ in range( col_amount ) ] for _ in range( row_amount ) ]
print(f'{ two_dimentional_arr }')
# [[1, 1], [1, 1], [1, 1]]
Remark:
col_amountis placed in the INNER loop androw_amountis placed in OUTER loop. (I learnt this when I was fixing a bug in the coding test practice)When you need to apply Cartesian coordinate with the 2 dimentional array, the position will be switched:
- x coordinate = COLUMN number in 2 dimentional array
y coordinate = ROW number in 2 dimentional array
e.g. The point (2,0) in Cartesian coordinate
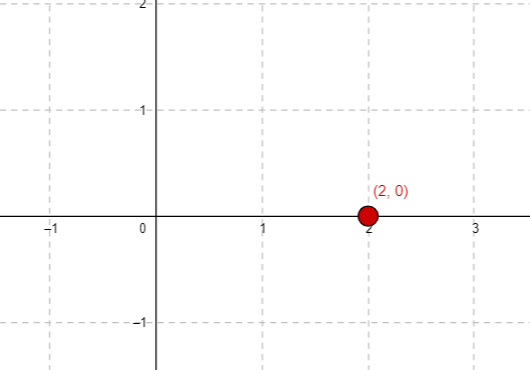
In 2 dimentional array, the same position is
array[0][2]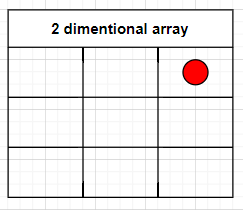
3. Map, Filter
map and filter can do the same thing but the concept is different:
mapconverts an existing list to a new list by applying a function to each elementfilteris to generate a new list by filtering an existing list with a function
fruits = ["apple", "banana", "cherry", "kiwi", "mango"]
upper_fruits = list( map( lambda fruit: fruit.upper(), fruits ) )
print(f'{ upper_fruits= }')
# upper_fruits= ['APPLE', 'BANANA', 'CHERRY', 'KIWI', 'MANGO']
fruits_with_a = list( filter( lambda fruit: "a" in fruit, fruits ) )
print(f'{ fruits_with_a= }')
# fruits_with_a= ['apple', 'banana', 'mango']
4. List Comprehension vs. Map, Filter
Which way is better? 🤔
You may find a long debate about this topic on Internet. I personally prefer ninjagecko's answer and I tidied up and added my own opinion as follow:
Usually, use list comprehension instead of
map,filterorreducesince list comprehesion is more intuitive and readable.In some special case, like constructing multi-dimentional array, using list comprehension is easier
Use
map,filterorreduceif there is a function already defined to carry out the actionFor example, we would like to convert
"1 2 3 4 5"to a list of integer and functionintis usedinput_text = "1 2 3 4 5" int_list = list( map( int, input_text.split() ) ) print(f'{ int_list= }') # int_list= [1, 2, 3, 4, 5] int_list = [ int( x ) for x in input_text.split() ] print(f'{ int_list= }') # int_list= [1, 2, 3, 4, 5]mapis better in this example as it does not need to declare an extra variablexas in list comprehension.However, it may lose readability to novoice programmer when they read your code
Use
for-loop you need to do some complex operation insides the looplist comprehension is only work in python and cannot apply to other languages, but the concept of
map,filterorreduceexists in other programming languages as well, like JavaScript, C#
5. Sort
List can be sorted by calling .sort() or sorted(). The difference between two is that list.sort() is sorted the list itself without output, while sorted() returns a new sorted list.
prime_numbers = [11, 3, 7, 5, 2, 13]
prime_numbers.sort()
print(f'{ prime_numbers = }')
# prime_numbers = [2, 3, 5, 7, 11, 13]
prime_numbers_sorted = sorted( prime_numbers, reverse=True)
print(f'{ prime_numbers_sorted = }')
# prime_numbers_sorted = [13, 11, 7, 5, 3, 2]
5.1. Custom Sort with key
If we need to sort with a complex requirement, then we need to use key function. e.g. sorting employees by employee's name in ascending order.
employees = [
{'Name': 'Alan Turing', 'age': 25, 'salary': 10000},
{'Name': 'Sharon Lin', 'age': 30, 'salary': 8000},
{'Name': 'John Hopkins', 'age': 18, 'salary': 10000},
{'Name': 'Mikhail Tal', 'age': 40, 'salary': 15000},
]
employees.sort(key=lambda employee:employee['Name'])
employee_names = [ employee[ "Name" ] for employee in employees ]
print(f'{ employee_names = }')
# employee_names = ['Alan Turing', 'John Hopkins', 'Mikhail Tal', 'Sharon Lin']
If you need to sort multiple key, e.g., salary in decending order, age in ascending order and name in ascending order, then you need to apply lambda e: ( -1 * e["salary"], e["age"], e["Name"] ) to the key function in sort.
employees = [
{'Name': 'Alan Turing', 'age': 25, 'salary': 10000},
{'Name': 'Sharon Lin', 'age': 30, 'salary': 8000},
{'Name': 'John Hopkins', 'age': 25, 'salary': 10000},
{'Name': 'Mikhail Tal', 'age': 40, 'salary': 15000},
{'Name': 'Bruce Lee', 'age': 40, 'salary': 12000},
{'Name': 'Harry Potter', 'age': 30, 'salary': 12000}
]
employees.sort( key=lambda e: ( -1 * e["salary"], e["age"], e["Name"] ) )
for employee in employees:
print(f'{ employee }')
# {'Name': 'Mikhail Tal', 'age': 40, 'salary': 15000}
# {'Name': 'Harry Potter', 'age': 30, 'salary': 12000}
# {'Name': 'Bruce Lee', 'age': 40, 'salary': 12000}
# {'Name': 'Alan Turing', 'age': 25, 'salary': 10000}
# {'Name': 'John Hopkins', 'age': 25, 'salary': 10000}
# {'Name': 'Sharon Lin', 'age': 30, 'salary': 8000}
5.2. Custom Sort with comparator function
You can use cmp_to_key to convert a comparator function to a key function so it can be used by sort or sorted
import functools
employees = [
{'Name': 'Alan Turing', 'age': 25, 'salary': 10000},
{'Name': 'Sharon Lin', 'age': 30, 'salary': 8000},
{'Name': 'John Hopkins', 'age': 18, 'salary': 10000},
{'Name': 'Mikhail Tal', 'age': 40, 'salary': 15000},
]
def mycmp( e1, e2 ):
e1_name, e2_name = e1['Name'], e2['Name']
if e1_name > e2_name:
return 1
elif e1_name < e2_name:
return -1
else:
return 0
print(f'{ sorted( employees, key=functools.cmp_to_key(mycmp) ) }')
# [{'Name': 'Alan Turing', 'age': 25, 'salary': 10000}, {'Name': 'John Hopkins', 'age': 18, 'salary': 10000}, {'Name': 'Mikhail Tal', 'age': 40, 'salary': 15000}, {'Name': 'Sharon Lin', 'age': 30, 'salary': 8000}]
6. zip, for 2 same size list in parallel
If you have 2 lists with same size and would like to use one for-loop, zip is the solution.
str_list = [ 'a', 'b', 'c', 'd' ]
num_list = [ 1, 2, 3, 4 ]
for string, num in zip(str_list, num_list):
print(f'{ string, num }')
# ('a', 1)
# ('b', 2)
# ('c', 3)
# ('d', 4)
7. Precaution, generating a list of a single item
You can generate a list of a single item by list comprehension or *, e.g.
list1 = [ 1 for _ in range(4) ]
list2 = [ 1 ] * 4
print(f'{ list1= }')
print(f'{ list2= }', end='\n\n')
# list1= [1, 1, 1, 1]
# list2= [1, 1, 1, 1]
list1[ 0 ] = 0
list2[ 0 ] = 0
print(f'{ list1= }')
print(f'{ list2= }')
# list1= [0, 1, 1, 1]
# list2= [0, 1, 1, 1]
But if the single item is a list, the following problem will occurs.
list1 = [ [ 1 ] for _ in range(4) ]
list2 = [ [ 1 ] ] * 4
print(f'{ list1= }')
print(f'{ list2= }', end='\n\n')
# list1= [[1], [1], [1], [1]]
# list2= [[1], [1], [1], [1]]
list1[ 0 ].append( 2 )
list2[ 0 ].append( 2 )
print(f'{ list1= }')
print(f'{ list2= }')
# list1= [[1, 2], [1], [1], [1]]
# list2= [[1, 2], [1, 2], [1, 2], [1, 2]]
In list2, we only append 2 in the first element but all elements in list2 has been appended 2.
In the 1st example, since the single element is an integer, which is immutable. When we assign a new value to the first element of the list, we actually create a new instance and replace the original element in the list.
In the 2nd example, we need to understand the difference between list comprehension and using *:
[ [ 1 ] for _ in range(4) ]= generate a list of elements which each element is a DIFFERENT list[1][ [ 1 ] ] * 4= generate a list of elements[1], which are reference to the SAME element
list1 = [ [ 1 ] for _ in range(4) ]
list2 = [ [ 1 ] ] * 4
for element in list1:
print(f'list1,{ id( element )=}')
# list1, id( element )=1945471559360
# list1, id( element )=1945475077120
# list1, id( element )=1945475077056
# list1, id( element )=1945475076864
for element in list2:
print(f'list2,{ id( element )=}')
# list2, id( element )=1945475076800
# list2, id( element )=1945475076800
# list2, id( element )=1945475076800
# list2, id( element )=1945475076800




